- A+
引 言
近年来,VoIP(Voice over IP)技术及其业务的迅速发展,对传统的电信业务造成了巨大的冲击,与传统电话相比,IP电话以其网络带宽利用率高,通话成本低,可灵活地提供丰富的增值功能而备受市场青睐。然而,由于VoIP的语音在与其他数据一起在网络中传输时要经过压缩、编码、打包等一系列处理,造成回声路径的延迟较大,延迟抖动也较大,严重影响了话音质量,阻碍了VoIP市场的拓展。因此,在VoIP终端上增加回声消除算法已成为必然。
1 声学回声消除技术的原理
1.1 声学回声产生原理
根据回声的产生原因,回声可以分为声学回声和电学回声两类。电学回声是由于电路阻抗不匹配造成的,通常影响比较小。随着消除回声技术的发展,当前回声消除研究的重点已由“电学回声”的消除转向了“声学回声”的消除。声学回声指设备的一部分声音信号回馈到同一设备的受话器,分为直接回声和间接回声。直接回声指扬声器的声音未经任何反射直接进入麦克风,这种回声延迟最短。间接回声是指扬声器播放的声音经不同的路径一次或多次反射后进入麦克风所产生的回声集合,其主要特点是回声路径冲激响应变化范围大,变化快,冲激响应持续时间长,一般在50~300 ms。这使得自适应建模滤波器的阶数很高,因而成为语音通信系统回声的主要难题。
1.2 声学回声消除的原理
自适应回声抵消的基本思想是估计回声路径的特征参数,产生一个模拟的回音路径,得出模拟回声信号,从接收信号中减去该信号,实现回声抵消。图1给出了单向传输的声学消回声器AEC的原理图。
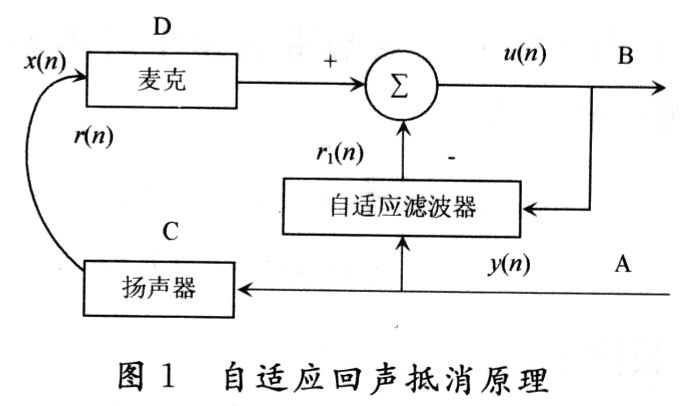
图1中,y(n)代表来自远端的信号;r(n)是经过回声通道而产生的不期望的回声;x(n)是近端的语音信号;D口的近端信号叠加有不期望的回声。对消回声器来说,接收到的远端信号作为参考信号,消回声器根据由自适应滤波器产生回声估计值,将r1(n)从近端带有回声的语音信号减去,就得到近端传送出去的信号μ(n)=x(n)+r(n)-r1(n)。在理想情况下,经过消回声处理后,残留的回声误差e(n)=r(n)-r1(n)将为0,从而实现回音消除。
2 自适应回声消除算法理论
回声消除理论的难点是估计回声与近端输入信号之间的同步问题以及如何对双端讲话进行处理的问题,若这两个问题处理不好,就会造成滤波器的发散,不但不能消除回声,反而会引入更烦人的噪声。
2.1 双端话音处理与MDF算法结合
在NLMS算法中,假设输入近端背景噪声与远端信号均为白噪声,那么两信号间为时间无关的,因此可以求得最优步长因子:
![]()
式中:r(n)为残留回声的方差的估计值;e(n)为误差信号的方差的估计值。
但是用LMS/NLMS算法来进行语音信号的声学回声消除时,两信号时间无关的假设就不完全成立,因此只能借助于频域处理法。MDF算法相当于对每一个频率使用NLMS算法。为了解决双端讲话检测这个难题,文献[6]提出了一种与MDF相结合的不需要显式进行双端话音检测的方法,以下是推导。由于信号在频域的相关程度比在时域的相关程度小得多,而且步长因子μ也可以变换到频率域μ(k,l),即有公式:
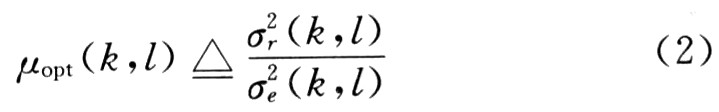
式中:k为输入信号块索引号;l为信号频率。假定残留回声是泄漏因子η(l)与回声估计值的乘积,即:
![]()
又因为步长因子需要在双端讲话发生时迅速对其做出反应,故可以有等式:
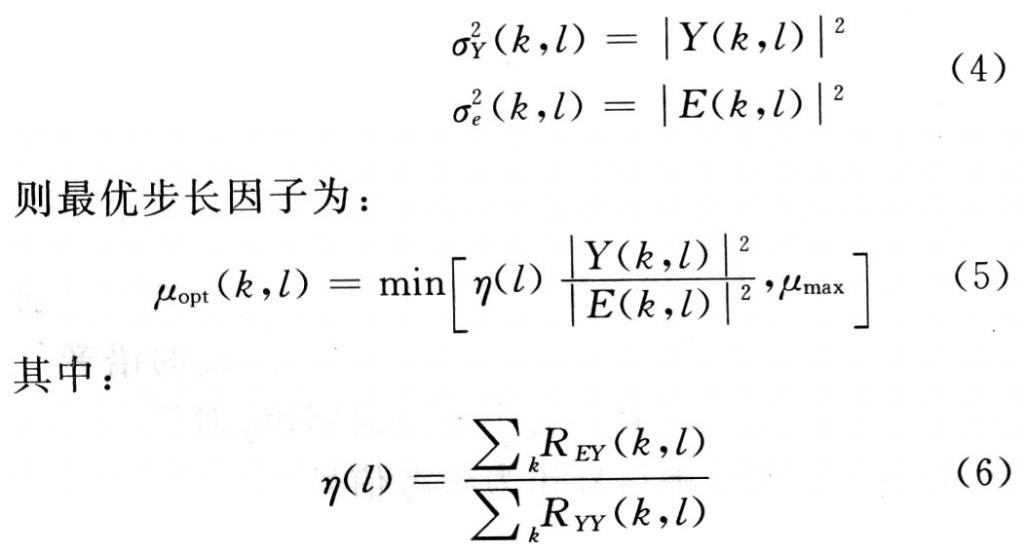
分子代表估计回声与误差信号的互相关值,分母为估计回声的自相关值。若有双端讲话存在,则误差就会变得很大,因此步长因子就会变得非常小,不会使滤波器系数变化太大;若有背景噪声存在,由于步长因子公式中,分子分母都有噪声的影响,因此相互抵消后噪声的影响也会变得非常小了。
2.2 估计回声与近端输入信号的同步
回声消除的原理就是利用参考回声与真实回声之间的相关性,因此播放声音的线程和录音线程之间的同步就显得极为重要。下面分两步进行处理:
第一步,输入/输出设备与处理器之间存在速度不匹配的问题,为了改善这个矛盾,需要在输入/输出端分别划出若干个专用缓冲区。在本测试环境中,输入/输出流的延迟经过计算结果为10帧,也就是从处理器把第一帧要播放的声音放人参考回声帧队列算起,到处理器从参考回声帧队列中取出一帧来与第一帧录音输入进行回声消除时为止,录音输入比参考回声在时间上落后了10帧。也就是说,这前10帧录音输入不用进行回声消除,而是直接传走,这个过程就称为预取。
第二步,实际应用中播放声音和录音是用两个线程完成的,所以仅仅用上面固定的延迟数量来同步参考回声和录音输入这两个信号还不行。设一个变量rec_ts作为处理器要处理的录音输入帧的序列号,设play_ts作为处理器处理的参考回声帧的序列号。用seq_delay=play_ts-rec_ts来修正上面的预取过程。当Seq_delay>0时,证明播放线程比录音线程快,因此则减少录音输入帧的预取个数;当Seq-delay<0时,证明播放线程比录音线程慢,因此则增加录音输入帧的预取个数。
3 测试及结论
Speex是一个开源、免费、专门针对VoIP语音的编解码器,是一种动态比特率编码方式,它意味着可以根据网络环境的变化来动态地修改其比特率,它在窄带和宽带中都提供相应版本。回音消除一直是VoIP中亟待解决的主要问题,所以近年来Speex中也集成了回音消除的模块。因为Speex算法中,AEC没有考虑线程同步问题,因此这里提出了一种使播放线程和录音线程同步的方法。
用PC机在VC 6.O下建工程进行测试。用麦克将一段语音录下,存为ref.pcm,之后用音箱把这段录音播放出来,播放的同时再用麦克将其录下,等播放一段时间后(代表只有远端讲话的情况),再有人开始讲话,这时的录音就代表双端讲话的情况,把该文件存为echo.pcm。测试时采样率为8 000 Hz,20 ms为一帧,/μmax=1。
回声抵消效果一般还采用回声返回衰减增益(ERLE)来评价,其定义如下:
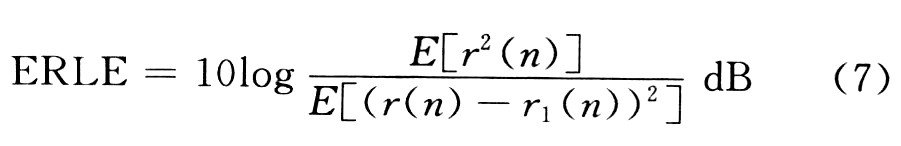
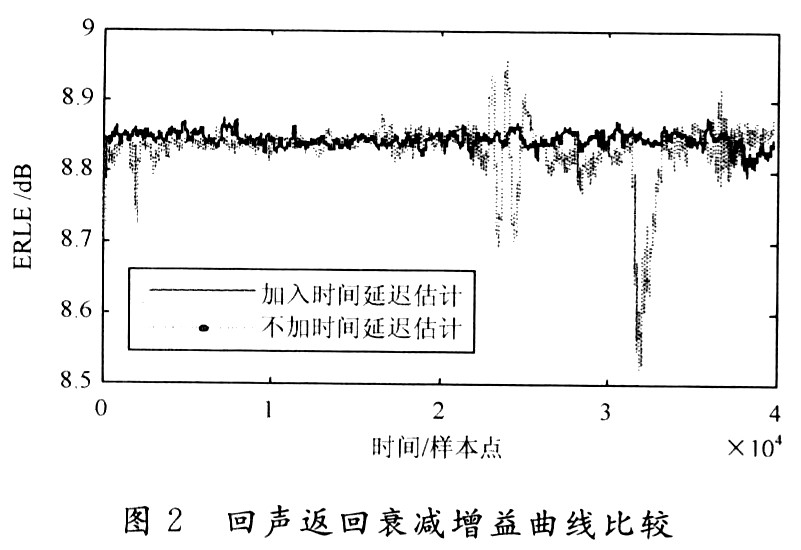
ERLE值越大,则表明回声抵消效果越好,一般要求ERLE≥6 dB。测试回声返回衰减增益如图2所示。由图2可知,加入时间延迟估计后的效果好于不加时间延迟估计的效果。
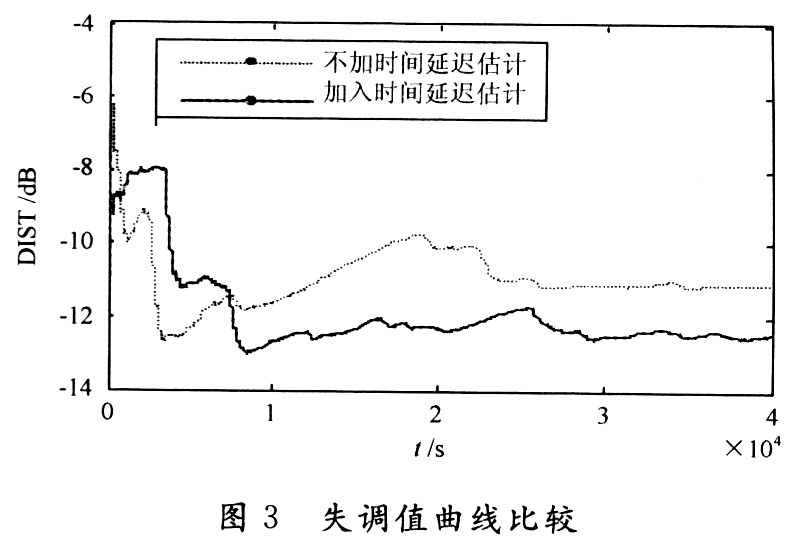
失调也称为系统距离(DIST),反映的是回声消除器中自适应FIR滤波器r1(n)对真实回声路径r(n)的逼近程度。其定义如下:
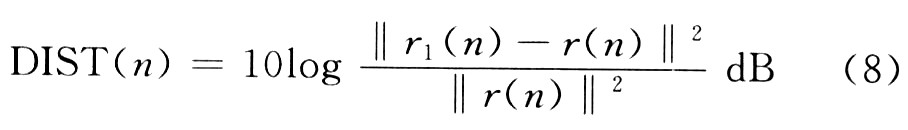
DIST值越低,表明自适应滤波器收敛性能越好。由图3也可看出,加入时间延迟估计后的失调量总体上低于不加时间延迟估计的失调量。
通过测试和大量的通话主观测试,结果表明,用该方法实现的声学回声消除器能够满足通信对语音的要求,因此为VoIP语音通信和移动通信终端提供了参考。