- A+
语音通话开发,对于一般开发者来说比较神秘,很多朋友不太清楚如何全面的评估第三方的音频引擎,如何科学的选择一家靠谱的语音通话服务供应商。
很多朋友还停留在这样的初级阶段:把demo调通,找几个人喂喂喂……凭自己优异的听觉感受一下。整个测试过程就完成了,厂商也就这么“愉快”的选定了。但是,少年!如果你这样选,你很有可能遇到下面的这些坑:
- 我们花了好多钱买了一套基于硬件的解决方案,开始用的还行,怎么现在越来越卡了?
- 我们评估了个引擎,自己内网测试的时候感觉声音很流畅,延时很小。为什么上线了很多用户说又卡又延时啊?
- 我们用WebRTC做了一套方案,iPhone上还好,但是为什么在安卓的机器上老是有回声啊?
- 为什么我昨天用的还好好的,今天换了个手机/地方/网络打效果差好多啊?
这篇文章,就会教你如何科学的选择一家靠谱的语音通话服务供应商。这是本文提纲。今天看不完不要紧,收藏起来用到的时候拿出来翻翻。
- 首先,普及一下,哪些因素会影响对音频质量的评估。
- 然后,我们再来看需要做哪些测试。
- 最后,我们讨论一下大家比较关心的WebRTC框架中的音频模块如何,是否适合商用?
文章有点长,看不完不要紧,收藏起来,用到的时候拿出来翻翻。
影响音频质量和稳定性的因素到底有哪些呢?
1.网络(丢包 延时 抖动)
网络对音频质量的影响是非常直观的,如果承载音频信息的语音包在网络传输的过程中丢失,晚到,或者不均匀的到,就会造成我们常说的丢包,延时和抖动。
从主观听感上造成声音的卡顿和滞后,严重影响通话的质量和可懂度。在公共互联网上的,特别是在远距离通信的情况下,如果缺乏足够的网络部署和音频的丢包对抗技术,这种情况就会变得尤为明显。如果是在内网环境,两人通话的场景下,声音可以通过点对点(P2P)的连接互相传输,很多网络问题容易被单一的测试环境忽略了。
这也是为什么有些同学在自己的公司内网测试时候感觉延时小声音流畅,跑到真实环境下就经常遇到各种各样的质量问题。
另外值得一提的是,除了在传输层引起的丢包抖动,最后一公里(Last Mile)的问题(路由器,移动数据网络等)也会引起丢包抖动,所以有时候有的同学说我们家20M的带宽,怎么用起来还是卡顿。其实有时候路由器反而是产生问题的根源。
2.设备 (声学设计,计算能力)
设备对于音频质量的影响是相对隐性的,但是往往会起着决定性的作用。比如iPhone就有着比较好的声学设计。麦克风和扬声器之间的耦合程度较小,这样你说话经扬声器播放产生的回声在被麦克风收录时候已经有了很大程度的衰减,对回声消除模块来说也是一个利好。另外它有三个麦克风,位于设备底部的麦克风主要收取说话人的声音,位于背部的麦克风用来拾取背景噪声,给主麦克风做参考,从而更好对人声做降噪处理,让对方听得更清楚。另外位于听筒附近还有一个麦克风用来感知听筒附近的噪声,从而生成一个反相位的波从听筒里播放出来抵消这部分噪声,让你听对方也可以听的更清楚。
而设备的问题在安卓机上就非常碎片化,我想所有和安卓打过交道的开发者都没少听过适配这两字。由于每个设备扬声器和麦克风的属性都不尽相同,特别是在一些中低端机型上有些手机的声学设计是非常不合理的(严重的麦克风扬声器耦合,非线性失真,麦克风底噪等),会使得一些通用的音频算法(回声消除,降噪)无法正常工作。这也回答了我们之前的问题,为什么有些同学测的iPhone觉得不错,但是到一些中低端的安卓机器上就问题百出。这类问题无论网络好坏都会产生,这时候就必须有音频引擎的算法模块来做对应的算法适应和适配了。除此之外,在手机这类非实时操作系统上,计算资源的抢占,录放音的调度问题都会对音频算法带来很大的挑战。要解决这些问题就必须投入大量的资源去研发和调试,而解决这类问题的技术门槛一般都是很高的。
3.物理环境 (密闭环境,噪声, 啸叫等)
物理环境对音频的影响更不容易被察觉,但是它在很多情况下会干扰到音频引擎的正常工作,从而对用户的最终听感产生负面影响。熟悉音频算法的朋友都知道,我们在做回声消除的时候,需要实时估计出当前物理环境的脉冲响应(Impulse response),才能将它和参考信号(Reference signal)卷积,从而初步估算出麦克风收到的回声信号。假设我们现在身处一个密闭的会议室,扬声器播放出来的回声部分在被麦克风收录时候就会掺入很多物理环境反射路径带来的分量,这个时候就要考察自适应滤波器是否有足够的能力来覆盖这种场景了。如果音频引擎做得不好,就会导致我们平时遇到的一些奇怪现象,比如为什么我刚才听对方好好的,他换了个小会议继续开会我就很多奇怪的杂音呢?而事实上,影响脉冲响应的因素远不止这些,甚至有研究发现每一度温度的变化可能会导致40dB脉冲响应的变化。
另外还有很多物理环境会对音频质量造成影响。比如近场时候的尖锐杂音(啸叫),是由于设备A的麦克风会直接收录到设备B的扬声器播放的声音,然后又会传回设备B播放出来,形成了一个正反馈回环导致的。只要分开一定距离通话或者静音掉其中一方就会消失。更直观的例子比如本地身处嘈杂的环境下的听对方会更困难,对方听自己也会有受到噪声的干扰。再比如刚才说的密闭环境下,本身想保留的语音信号也会受到反射路径的影响,造成平时所说的混响(Reverb), 会让对方听到一些失真。
从上文的讨论中我们可以看到,其实网络,设备和物理环境都会对音频质量造成很大的影响,而且这种影响很多时候并非很直观的可以察觉到。如果没有科学的评估和定量的分析,很难通过一两次测试来下比较全面和准确的结论。那么我们很自然的会问,我们需要怎样来定量和全面的评估一个音频引擎呢?要做哪些测试才能覆盖到尽量多的真是使用场景,同时又能尽可能的排除各种随机的影响因素呢?那么下面这章我就来讨论下这个问题。
要全面的评估一个第三方音频引擎需要做哪些测试?
1.客观测试
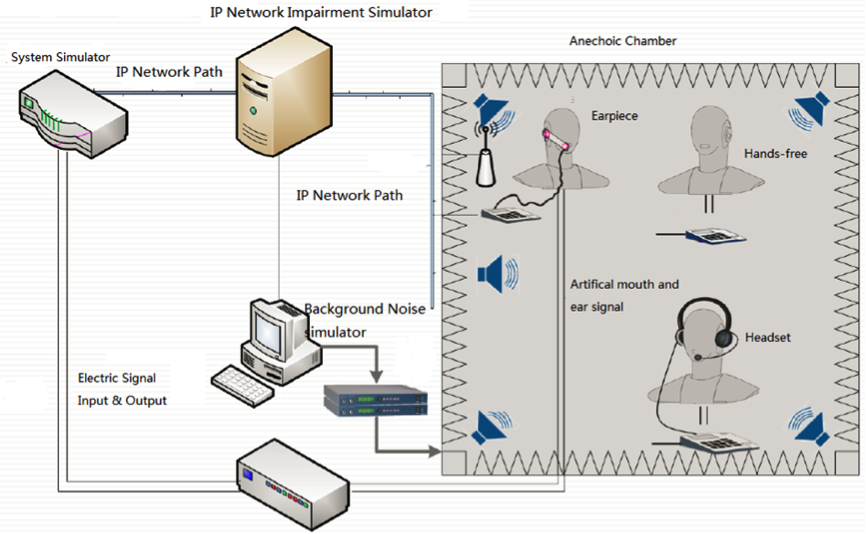
我们想要定量的分析一个音频引擎的优劣点,就必须在测试中尽可能的排除网络,设备和物理环境等因素带来的随机性影响。3GPP,ESTI等通信业国际标准,对手机通信的测试环境方法很多要求和指引,感兴趣的同学可以在参考文献找到一些资料。简单的说,我们需要足够安静且反射路径最小化的声学环境来避免周围的环境音来影响测试,所以需要有专业设计的消声室。我们需要可重复又高保真的发声和收音装置来覆盖人的正常说话和听力动态范围,所以需要人工耳和人工嘴。另外,为了覆盖更多的真实场景,我们还需要网损设备来模拟和控制丢包,需要近似真实环境的沉浸式噪音场景,我们需要在人工头的四周布置高保真的音箱来制造噪声声场。

要执行符合3GPP,ETSI等通信标准的客观测试,我们需要搭建了类似下图的测试环境。以Head Acoustic的ACQUA系统为例,我们需要:
- 将被测设备(DUT)置于消声室内,根据听筒,耳机和外放模式对应的标准距离和方法固定被测设备。
- 参考设备(RD)放在消声室外,通过Line-in线从测量前端(MFE)输入标准的语音序列。
- 做发送端的测量时,DUT接收到人工嘴的语音信号,经过对应的音频模块和网络传输处理,由消声室外的RD收到解码并送入MFE计算得分。
- 做接收端的测量时,参考信号由MFE灌入RD,经过网络传输被DUT收到解码播放,人工耳记录下从DUT播放出来的声音与参考信号比较计算得分。
- 网损模拟装置控制在发送端或者接收端加入不同类型的丢包,延时和抖动,来测量不利网络环境下的引擎表现
- 背景噪声模拟装置在消声室环境中制造不同信噪比和噪声类型的环境噪声,测试音频模块的降噪效果。
当我们搭建好了实验室的环境,根据3GPP的标准,我们可以通过这套环境来定量的测量到一些端到端的音频指标了。同样以ACQUA为例,我们可以测量但不限于: - End-to-End Voice Delay(ms):端到端延时,记录从RD到DUT的端到端的语音延时,涵盖设备和网络的延时。
- Echo Attenuation(dB):回声抑制,测量回声被抑制了多少,单位是分贝,一般>60dB的数值回声就不太容易被感知到了。
- POLQA: ITU较新的评估语音质量的指标,是以前PESQ的升级版,可以测量32KHz的采样率的语音。一般都通俗的把这类语音质量的评分称为MOS分,1-5分越高说明语音质量越好。
- 3QUEST: 同样是类似MOS分的语音质量测量,但是专门在噪声环境下进行,噪声声场需要有严格规定,噪声序列还需要参考相关标准。
- Loudness Rating (dB):响度评分,测量人工耳可以声压级(SPL), 一般在[-20,20]范围内比较理想。
- Idle Channel Noise (dB):空闲信道噪声,测量在没有语音活跃的状态下噪声的舒适度。这个值一般不高于-50dB
- Frequency Response (dB): 频响, 在相关标准中有频响曲线的掩蔽区间,测量分对应的是真实频响高于掩蔽区间的分贝数,所以越高越好。
- Signal-to-Distortion ratio (dB):信号失真比,在MFE记录下语音信号和失真直接的比值,数值越高说明语音保真度越高。
- Double Talk (dB):双讲,记录下语音在近端远端同时说话的时候的抑制情况,分数越低,说明双讲透明度越高,也就是语音的保留度更好。
客观测试的一个重要优点是,网络设备物理环境条件相对可控,可重复性较强。这些通信标准定义的客观指标也很大程度上可以帮助快速定位音频问题。但是客观测试本身也它自己的局限性。首先,要搭建上述的一套科学的客观测试环境,一般需要七位数字人民币的预算,这对很多公司来说已经是个很大的制约了。更重要的是,客观测试可以暴露一些明显的问题,但是很难覆盖到一些细节和定位到问题的根源。 所以无论是出于成本的考虑还是更细节的音频分析,我们都需要有合理的主观测试来弥补客观测试的一些问题。
2.主观测试
在业界,音频主观测试并没有可以统一遵循的标准。虽然ITU对音频主观测试有一些建议和指引,但是每个测试都有自身的侧重点设计和执行也不尽相同。
一般比较常用的做法是请足够多的人来采集有统计意义的样本,然后对测试人员做一定的听音培训。最后根据信号失真度,背景侵入度,和总体质量等方面来对音频通话打分。
这种方法主要用来比较不同引擎之间的总体主观感受,如果需要更细节的发现和比较问题,还是需要跟针对性的测试。
主观测试相对来比较灵活,可以不必限定在消声室中进行。但是为了尽量避免我们之前的提到的设备网络环境的不确定因素,测试人员和被测设备需要分别放置于两个音源隔离的房间。网损的部分,可以使用Linux的TC NetEM模块模拟,如10%丢包设置命令为:tc qdisc add dev eth0 root netem loss 10%。 噪声的部分,如果没有ACQUA等分析系统提供的噪声源,可以使用NOISEX-92等学术研究中常用的语料库来代替。建议对通话进行录音,这样可以在测试后重听和标注,更好的分析问题。如果测试的引擎不带录音的话,可以在外放的而环境通过外部设备来录制。
一般我们先在较好的网络状态下测试音频的基础质量,然后慢慢增加丢包率来测试一个引擎抗丢包的边界。在tc的随机丢包模型下,声网Agora.io的抗丢包能力一般在70%左右,这部分和一般的音频引擎还是有比较明显的差异。另外在细节的音频模块方面也需要很多针对性的测试,比如回声消除,降噪,增益控制,近场啸叫,盲源分离等模块都可以有非常详细的细节指标可以跟踪。这里就借用声网Agora Video Call和某些竞品的对比测试报告,来举例说明下如何针对不同的算法模块做一些定量分析。对其他模块有兴趣欢迎联系我们讨论,这里就不一一展开了。
下图(a)和(b)比较了某竞品和声网SDK在降噪(NS)方面的表现。这里用的是NOISEX-92语料库中的Voice Babble,混音的信噪比是5dB。 通过录音和定量分析,我们可以看到在算法的收敛时间,降噪后的残留噪声,和有语音时候的信噪比方面,声网的音频引擎效果有明显的优势。 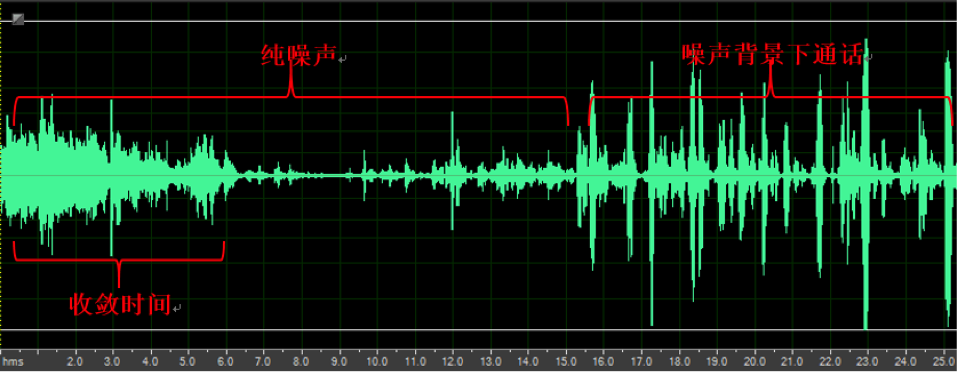
图(a)竞品 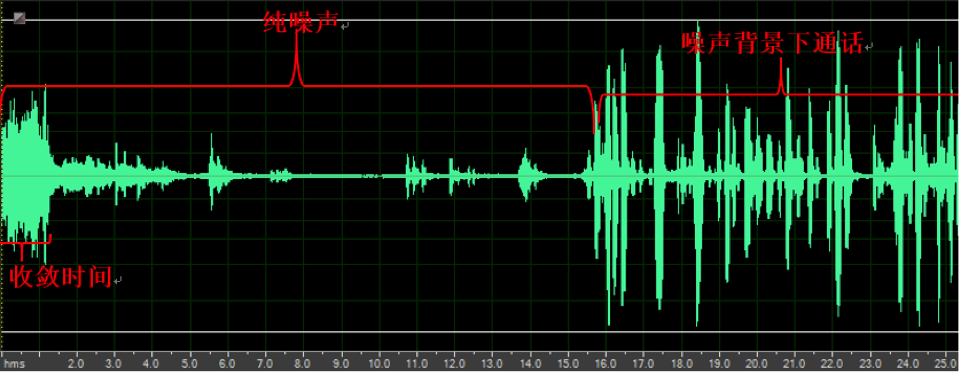
图(b)声网Agora.io
下图(c)和(d)比较了某竞品和声网SDK在自动增益控制(AGC)方面的表现。在会议场景中这个参数会特别重要。因为很有可能大家会离通话的设备有一定的距离说话,如果这时候不经过特殊的增益提高,对方会很难听清一些参会者的声音。从图中分析后可以发现,如果两边大家都贴近话筒的时候,录音的大家差异是不明显的。但是当你测试离麦克风有1米甚至2米的情况下,有些竞品的声音就会变的很小,而有正确的增益控制的引擎就能让你对音量均衡的声音。 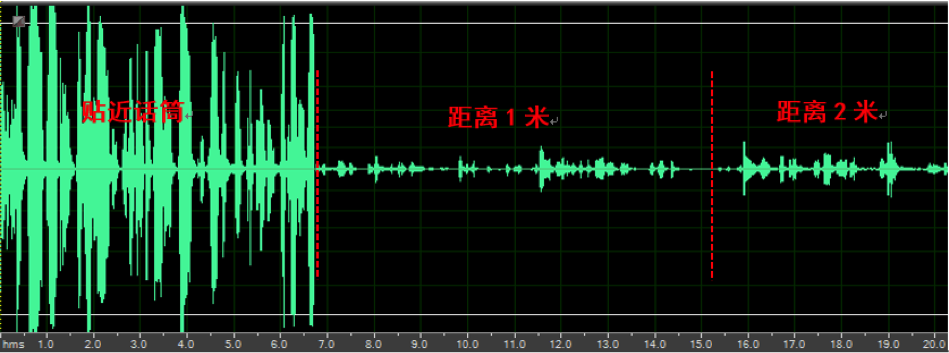
图(c)竞品 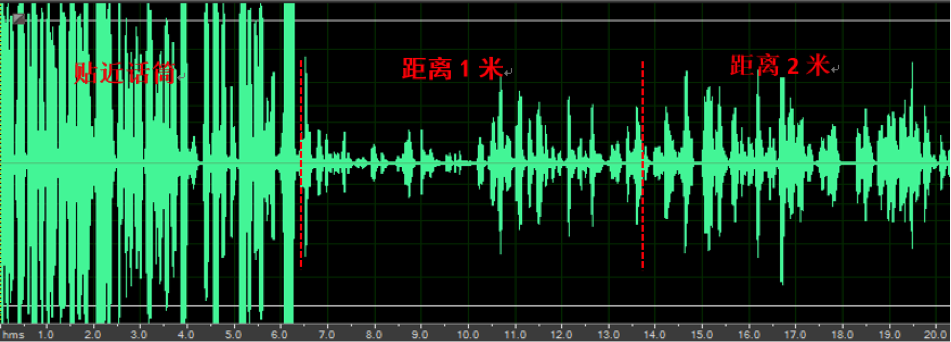
图(d)声网Agora.io
WebRTC的音频引擎怎么样?直接拿过来用可以吗?
到这里,大家应该对影响音频质量的因素和需要做哪些测试来评估一个音频引擎有了一定的概念。有的朋友可能会说,这个评估工作看起来都好复杂,也需要不少资源投入。有没有简单点的方法啊?听说WebRTC很火,可以直接拿来用吗?
声网公众号之前已经有一篇关于WebRTC的优缺点分析的文章,有兴趣的同学可以找出来看一下。那篇文章中提到的缺乏服务器部署,缺乏多人支持等缺陷这里就不赘述了,这里来稍微深入的探讨一下如果要用WebRTC音频模块来商用会遇到哪些问题。
移动端的优化不够
WebRTC最初是为PC上的浏览器通信而设计的,所以相关的音频算法,不管是从复杂度还是效果上都是以PC作为主要考量点的。虽然它也提供了像AECM这种专为mobile设计的低复杂度回声消除算法,但是效果一直被诟病。在其官方论坛也能找不少关于该算法导致的回声失真等问题的报告。而官方的答复是Won’t Fix, 理由是算法的已知缺陷。
对国产手机的“水土不服”
经过之前的讨论,我们已经知道设备对音频质量有很大的影响。这种影响在五花八门的国产手机,特别是一些中低端机型上尤为明显。如果让WebRTC音频模块直接在各种安卓机上跑的话,会遇到各种各样的问题。也有不少朋友现在还没有从这个坑里爬出来。这里不仅需要算法来适配补偿声学设计上的一些缺陷,也有不少是因为一些中小手机厂商没有遵循相关的安卓音频调用规范导致录放音问题,这时候还需要做机型相关的底层适配。
非商业运营,无文档无售后,遇到问题不好查
关于WebRTC音频模块的资料并不是很多,要了解每个算法模块的细节需要花不少时间,而且需要对信号处理有比较扎实基础的音频算法工程师才行。很多时候我们所说的适配只是一个通用的说法,并不是已经有很多开放出来的参数一个个试就能解决问题的。想要达到比较好的音频体验,对算法的理解和投入是必须的,否则遇到音频问题就会束手无策。虽然WebRTC会通过自己的论坛和Bug Report系统来收集一些用户问题, 但是要期望官方短期内解决还是需要多烧烧香的。
对复杂的应用场景支持不够
随着应用的多元化,我们开始需要在App里面定义多于一个的音频行为。比如在游戏场景中需要播放游戏音效的同时进行语音,比如在直播场景中主播需要把MP3等音乐文件和录音混音处理。这些部分都不在WebRTC的考虑范围之内,需要自己团队来做开发。
结论
网络,设备,物理环境都会影响音频质量,测试评估不要局限于单一环境。
全面的评估一个实时语音引擎需要科学的测试环境搭建和主客观测试流程。
要自己实现实时语音通话功能需要对音频有深入的研究和理解,不要轻信集成开源项目可以一劳永逸。
如果没有足够的开发资源和时间成本来自研实时语音引擎,尽量选择对音频有理解,有售后,靠谱的供应商。
【本文作者】
陈若非 声网Agora.io 资深音频技术专家
负责基础音频技术的架构和研发。毕业于香港城市大学Ph.D。 主要研究基于模型重建的语音增强技术,对回声消除,降噪,增益控制,多麦,音效处理,丢包隐藏等语音技术有丰富经验。曾任职YY基础技术研发部门,及为IEEE权威语音期刊和会议担任评审工作。
【参考文献】
[1] ITU-T P.863, “Perceptual objective listening quality assessment
(POLQA)” https://www.itu.int/rec/T-REC-P.863 [2] ETSI EG 202 39603,
“Speech Processing Transmission and Quality Aspects (STQ); Speech
Quality performance in the presence of background noise Part 3:
Background noise transmission - Objective test methods”
http://www.etsi.org/deliver/etsi_eg/202300_202399/20239603/01.02.01_50/eg_20239603v010201m.pdf
[3] ETSI TS 103 106, “Speech and multimedia Transmission Quality
(STQ); Speech quality performance in the presence of background noise:
Background noise transmission for mobile terminals-objective test
methods”
http://www.etsi.org/deliver/etsi_ts/103100_103199/103106/01.01.01_60/ts_103106v010101p.pdf
[4] ETSI ES 202 396-1, “Speech and multimedia Transmission Quality
(STQ); Speech quality performance in the presence of background noise
Part 1: Background noise simulation technique and background noise
database”
http://www.etsi.org/deliver/etsi_es/202300_202399/20239601/01.04.00_50/es_20239601v010400m.pdf
[5] ITU-T P.835, “Subjective test methodology for evaluating speech
communication systems that include noise suppression algorithm”
https://www.itu.int/rec/T-REC-P.835 [6] 3GPP TS 26.131 / ETSI TS 126
131, “Universal Mobile Telecommunications System (UMTS), LTE, Terminal
acoustic characteristics for telephony, Requirements”
http://www.etsi.org/deliver/etsi_ts/126100_126199/126131/12.02.00_60/ts_126131v120200p.pdf
[7] 3GPP TS 26.132 / ETSI TS 126 132, “Universal Mobile
Telecommunications System (UMTS), LTE, Speech and video telephony
terminal acoustic test specification”
http://www.etsi.org/deliver/etsi_TS/126100_126199/126132/11.00.00_60/ts_126132v110000p.pdf
[8] 3GPP TS 51.010-1 / ETSI TS 151 010-1, “Digital cellular
telecommunications system (Phase 2+); Mobile Station (MS) conformance
specification; Part 1: Conformance specification”
http://www.etsi.org/deliver/etsi_TS/151000_151099/15101001/10.03.00_60/ts_15101001v100300p.pdf



